
tg-me.com/knowledge_accumulator/69
Last Update:
Почему AlphaDev не перевернул всё вверх дном?
Поговорим о недавно вышедшей от Deepmind статье, в которой обучали нейросеть для поиска более быстрого алгоритма сортировки. Я уже рассказывал про статьи AlphaZero и AlphaTensor, использующих в сущности тот же самый метод (советую изучить)
Особенности данного случая:
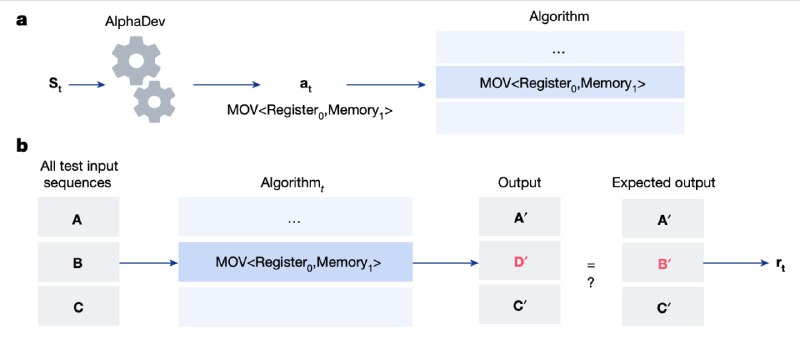
1) Пишем программу на ассемблере, генерируя команды по одной. Команды (действия) это элементарные операции сравнения, присваивания и т.д.
2) "Состоянием" в каждый момент является программа, сгенерированная на данный момент, и результат исполнения этой программы.
3) Наградой агента является штраф за длину программы (или время финального исполнения) и за неправильность итогового алгоритма, измеряемую тестами.
Какой результат?
Мы решаем по отдельности задачи создания алгоритма для сортировки массивов фиксированной длины. Начиная с длины 3 и заканчивая 8, выигрыш AlphaDev у человека составил 1, 0, 4, 3, 2, 1 операций. Интуитивно, а также по опыту AlphaTensor, кажется, что при увеличении размера входа нейросеть должна наращивать преимущество по сравнению с человеком, т.к. человеку гораздо сложнее работать с большим количеством объектов.
Почему здесь не так круто? Напишу свои гипотезы, буду рад почитать ваши мысли:
1) Нейросети с их многоразмерными неинтерпретируемыми представлениями не так хорошо дружат с дискретными командами в программировании. Это в принципе усложняет поиск.
2) Нам нужно сгенерировать более длинную последовательность команд, которая должна быть согласована между собой и порождать строгий алгоритм. Это мешает на больших входах.
3) Человек в принципе достаточно силён в программировании по сравнению с матричными перемножениями, поскольку это более близкая к человеческому мышлению вещь. Поэтому на маленьких входах мы уже смогли создать близкий к оптимальному алгоритм.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/69